
How have synthetic data helped improve breast cancer detection ?
ALIA SANTé

Discover how synthetic data can be used to improve breast cancer detection
Reading time: 3 minutes
Breast cancer
Breast cancer is the most common type of cancer among women in France, the European Union and the United States. Although this disease is the leading cause of cancer death in women in 2018, the number of cases diagnosed each year has been on a downward trend since 2005. If breast cancer is detected at an early stage, the chances of survival at 5 years are 99%. Early detection of breast cancer therefore has a significant impact on reducing the disease’s mortality rate.
AI in the service of medicine
A number of artificial intelligence tools currently exist to help healthcare professionals speed up diagnosis and facilitate therapeutic decisions. Using a combination of genomic sequencing data and Machine Learning algorithms, it is possible to fight cancer. Machine learning can help in the detection, treatment and prognosis of the disease. But also in the development of personalized treatments. This approach makes it possible to draw on data from multiple patients to identify similarities and correlations between them, and thus gain a better understanding of the disease.
However, artificial intelligence is currently hampered by the limited amount of data available. So how can we enable AI to break through this barrier and reach a new stage in its evolution?
To answer this question, we propose a use case on the “Breast Cancer Wisconsin (Diagnosis) – UCI Machine Learning Repository” dataset. The aim of this dataset is to predict whether a tumor is malignant or benign. We therefore decided to augment the training database with a classification artificial intelligence model using synthetic data.
The study
1,000 digital twins complemented the 569 real patients in this study. These digital twins are synthetic data generated using artificial intelligence algorithms. These algorithms faithfully reproduce the characteristics of the real patients, while preserving their anonymity. This approach has made it possible to extend the size of the training data set. This opens up new perspectives for artificial intelligence models.
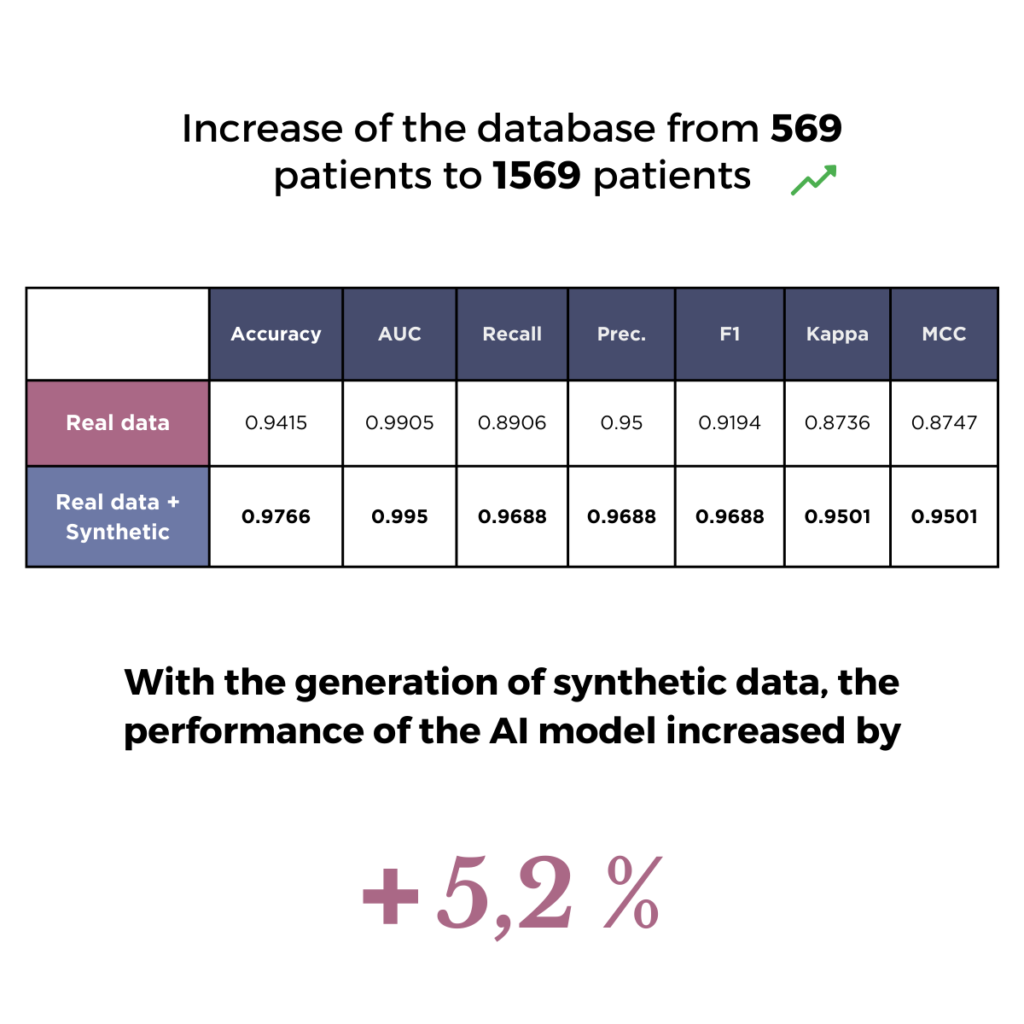
The comparison
We compared the performance of several classification models. The results showed a 5.2% improvement in the performance of models trained with a cohort combining real and virtual patients, compared with models trained only with real patients.
The benefits of synthetic data in this context are clear. The performance of artificial intelligence solutions for breast cancer classification is improved by the addition of synthetic data. This enables models to be more accurate and reliable in detecting both malignant and benign tumors. This can have a direct impact on treatment decisions taken by healthcare professionals.
By using synthetic data, it is then possible to considerably enlarge the size of the training dataset. This in turn enables models to learn from a more diverse and representative sample.
In addition, synthetic data have the advantage of being
of being anonymous, which solves the problems of confidentiality and
protection of sensitive patient data. Researchers and
and healthcare professionals can use these data without fear of violating
violate the privacy of the individuals concerned.
Conclusion :
Synthetic data contribute to the improvement of breast cancer.
The use of synthetic data has brought significant improvements in breast cancer detection thanks to artificial intelligence. The performance of classification models has been enhanced. This means better predictions and a larger database for research. While preserving patient confidentiality, synthetic data opens up new prospects for innovation in the fight against breast cancer. This promising approach paves the way for new advances in healthcare.
