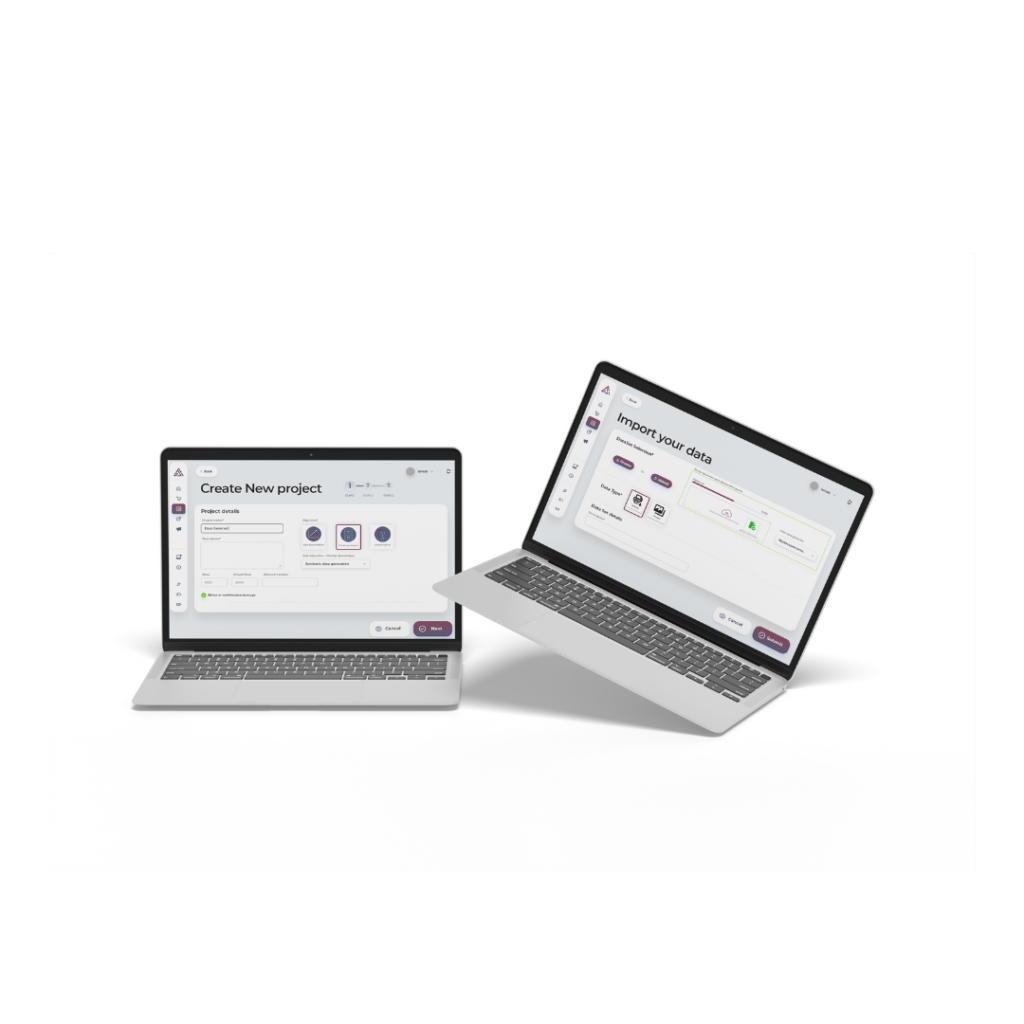
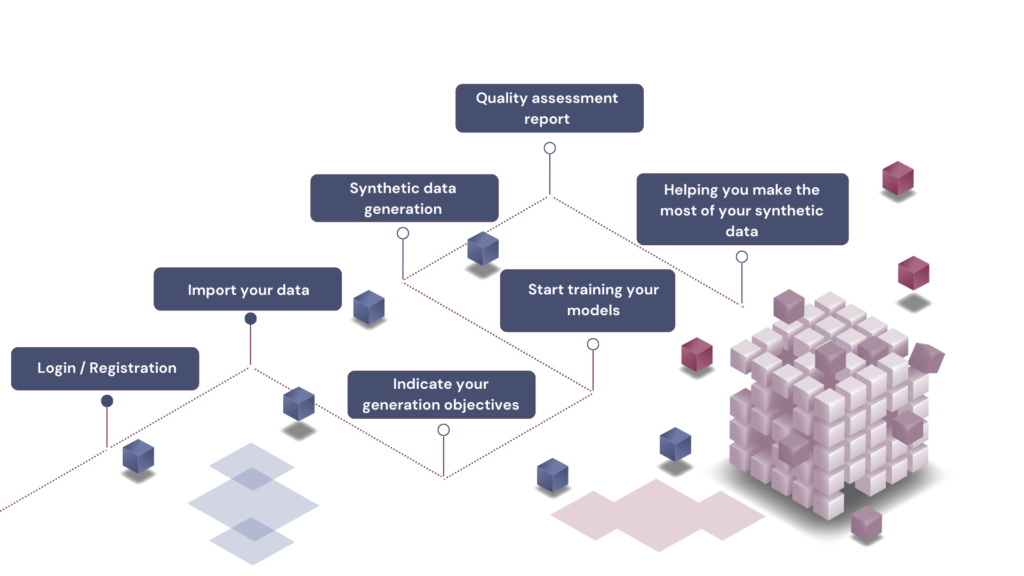
Use your synthetic data safely with our quality report.
Healthcare experts and statisticians verify the compliance and accuracy of your data, both initial and enriched. Alia DataGen automatically generates a Human Assurance Report, in compliance with the AI Act.
Assessment of synthetic data quality is based on data performance.