
Leveraging large language models to generate synthetic tabular data

LLMs and synthetic data
Reading time: 7 minutes
The constant evolution of artificial intelligence is opening up exciting new perspectives in the field of natural language processing (NLP).
At the heart of this technological revolution are Large Language Models (LLMs), deep learning models capable of understanding and generating text remarkably fluently and accurately. These LLMs have attracted considerable interest and become key players in many applications.
However, little research has been carried out on using such a model to generate synthetic tabular data, despite its generative nature.
Synthetic data generation is becoming an indispensable tool for various industries and domains. Whether for reasons of confidentiality, data access, cost or limited quantity, the ability to generate reliable, high-quality synthetic data can have a significant impact.
Follow us to find out how LLM can become a major asset for the generation of synthetic tabular data.
What is an LLM and how does it work?
Large language models (LLMs) are revolutionizing our interaction with natural language, as artificial intelligence models, often in the form of transformers. They are based on deep neural networks, trained with a vast corpus of Internet texts. This training enables them to achieve an unprecedented level of understanding of human language. Capable of performing a variety of linguistic tasks, such as translating, answering complex questions or composing paragraphs, LLMs prove to be extremely versatile. GPT-3, with its 175 billion parameters, illustrates the power of these models, positioning itself as one of the most advanced LLMs to date.
LLMs take into account the context of a sentence and develop in-depth knowledge of the syntax and subtleties of language. They aim to predict the most likely sequence of words given the current context, using advanced statistical techniques. In other words, they calculate the probability of words and word sequences in a specific context.
In the generation of synthetic data, the major advantage of LLMs lies in their ability to model complex data structures. They identify hierarchical information and interdependencies between different terms, mimicking the patterns found in real datasets. This ability to grasp complex relationships significantly enhances the quality of the synthetic data produced. Yet to date, few studies have exploited LLMs for the creation of synthetic tabular data. The question remains: how can a model originally designed for text create a realistic structured dataset with the appropriate columns and rows?
Let’s see how LLMs can be used to generate high-quality synthetic tabular data from a real dataset.
Modeling tabular data distributions with GReaT
LLMs and synthetic data
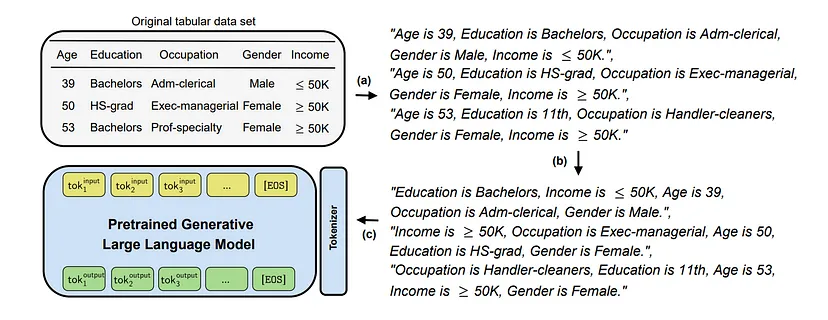
Each row of the database is transformed into a textual representation concatenating the column names with their variables using a concatenation operator.
For example, if our database has a “Price” column and the associated variable is “10€”, then the textual representation will be “The price is 10€”. Each row is then represented by expressing each variable as described above, separated by a comma. As the order of the variables in the resulting sentence is irrelevant when dealing with tabular data, a random permutation of the components is then performed to improve the final performance of the model.
How do you assess the quality of synthetic data?
Subsequently, fine-tuning is performed on an LLM pre-trained with the previously processed data. Finally, new synthetic data can be generated from the initial tabular data. To do this, several preconditioning options are available:
– If no value is specified, the model generates a sample representative of the distribution of data in the entire database.
– A characteristic-variable pair is given as input. From here, the model will complete the sample, imposing one variable and guiding the generation of the others.
– As in the previous case, it is also possible to impose several feature-variable pairs and further guide the generation.
Once the text sequences have been generated, an inverse transformation is performed to return to the original tabular format.
In summary, GReaT harnesses the power of LLM capabilities by using contextual understanding to generate high-quality synthetic tabular data, giving this method a significant advantage over more commonly used techniques such as GAN or VAE.
Generate data sets without training data
Using prompts and LLM to generate tabular data without an initial database represents an innovation in synthetic data creation. This method is particularly suitable when initial access to data is limited. It enables the rapid production of customized synthetic data sets, offering an alternative to techniques such as GAN, VAE, or GReaT, which depend on a pre-existing data set for training. This is useful, for example, for testing artificial intelligence models without real data.
Defining a precise prompt, which specifies the format and characteristics of the tabular data, is crucial. You need to specify the names of the columns and the desired number of rows. The LLM can then generate a synthetic dataset with the specified columns and number of rows.
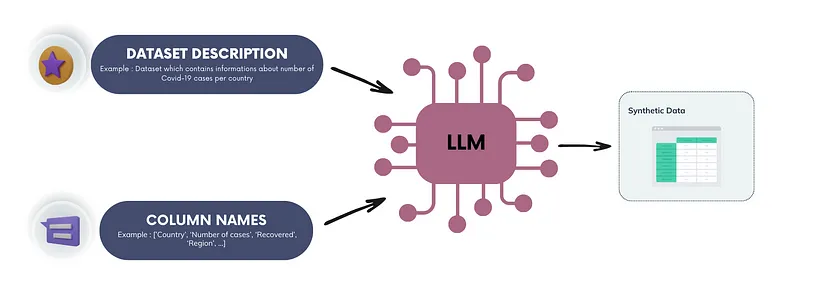
The prompt must first define the context of the dataset to make the most of the LLM’s language skills. It should also include column names and, except for the first few rows, the values of previous rows. In this way, the model can enrich the dataset while maintaining consistency of information.
Creating an effective prompt is the main challenge in generating realistic synthetic data. Often, it will be necessary to refine the prompt through several trials to achieve the desired accuracy. Results can be improved by providing additional details, such as column descriptions or variable formats.
Without a reference database, checking the quality and realism of synthetic data becomes complex. Careful evaluation by an expert therefore becomes essential to confirm their validity and adaptability to the context of use envisaged.
Conclusion
The rapid evolution of LLMs is revolutionizing text generation. Their complex architecture and high level of contextual understanding enable unprecedented text generation. Thanks to these capabilities, LLMs are finding applications in a variety of fields, including synthetic data generation.
For synthetic tabular data, LLMs show great promise. They excel at capturing complex contextual structures and relationships. This makes it possible to create more faithful and diversified synthetic data. The GReaT methodology illustrates the use of real data to train models generating high-quality synthetic data.
The prompt-based approach, with no prior training on real data, highlights the flexibility of LLMs. This fast, adaptable method opens up new avenues for generating synthetic data, especially when real data is limited.
LLMs can be used for more than just text generation. Their potential for achieving other objectives, such as the development of synthetic data, is immense.
