L’évolution constante de l’intelligence artificielle ouvre de nouvelles perspectives passionnantes dans le domaine du traitement du langage naturel (NLP).
Au cœur de cette révolution technologique se trouvent les Large Language Models (LLM), des modèles d’apprentissage profond capables de comprendre et de générer du texte de manière remarquablement fluide et précise. Ces LLM ont suscité un intérêt considérable et sont devenus des acteurs clés dans de nombreuses applications.
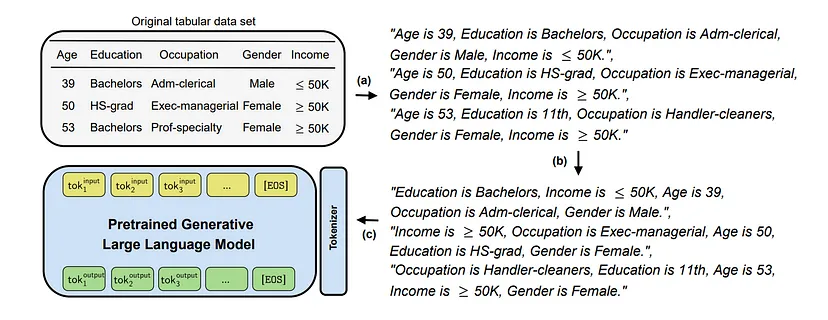
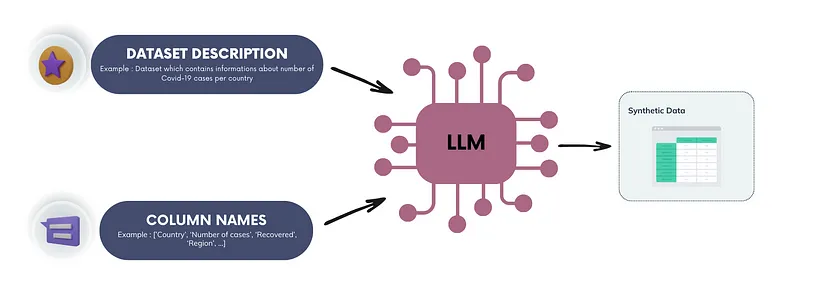
Cependant, peu de recherches ont été menées sur l’utilisation d’un tel modèle pour générer des données tabulaires synthétiques, malgré sa nature générative.