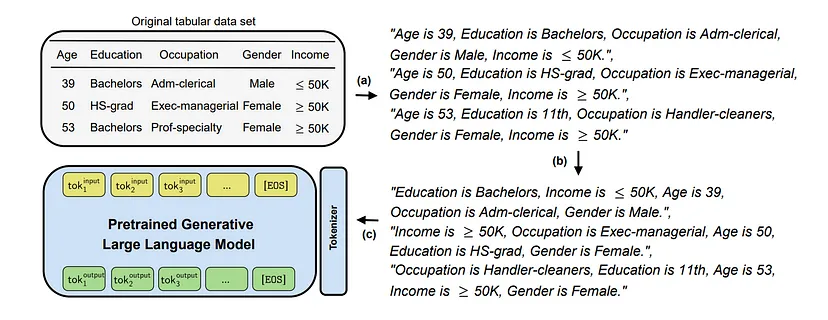
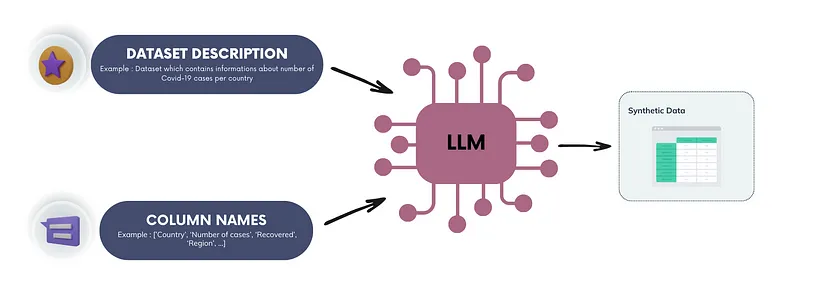
The constant evolution of artificial intelligence is opening up exciting new perspectives in the field of natural language processing (NLP).
At the heart of this technological revolution are Large Language Models (LLMs), deep learning models capable of understanding and generating text remarkably fluently and accurately.
These LLMs have generated considerable interest and have become key players in numerous applications. However, little research has been conducted on the use of such a model to generate synthetic tabular data, despite its generative nature.
Synthetic data generation is becoming an indispensable tool for various industries and fields. Whether for reasons of confidentiality, data access, cost, or limited quantity, the ability to generate reliable, high-quality synthetic data can have a significant impact. Follow us to discover how LLMs can become a major asset for synthetic tabular data generation.